


grep 对文本内容进行过滤,筛选
作用:grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来
可以联合正则表达式使用 Linux 正则表达式(私有)-口鸟人 (koniaoer.top)
语法:grep [参数] [匹配模式] [file]
参数:
-i:忽略大小写进行匹配
-v:反向查找,只打印不匹配的行
-n:显示匹配行的行号
-r:递归查找子目录中的文件
-l:只打印匹配的文件名
-c:只打印匹配的行数
-E:支持扩展的正则表达式符号
-q:静默模式,不输出任何信息
grep -n "root" koniaoer.txt #输出带有root的内容加行号
grep '^$' koniaoer.txt -n -v #排除空行,输出有用字符
grep '^#' koniaoer.txt -v #排除注释,输出有用字符sed 对文件或者数据流进行加工处理
作用:结合正则表达式对文件进行快速的增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串),取行(取出指定行)
可以联合正则表达式使用 Linux 正则表达式(私有)-口鸟人 (koniaoer.top)
语法:sed [参数] [sed内置命令] [file]
参数:
-e 以选项中指定的script来处理输入的文本文件
-f 以选项中指定的script文件来处理输入的文本文件
-i 直接将修改结果写入文件,不用-i,sed修改的是内存数据
-h 显示帮助
-n 取消默认sed输出仅显示script处理后的结果
-V 显示版本信息
-r 支持正则表达式扩展
sed内置命令:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 s/正则/替换内容/g ,结尾g表示全局匹配
sed匹配范围:
空地址: 全文处理
单地址: 指定的某一行
/模式/: 被模式匹配到的每一行
范围区间: 10,20 十到二十行 ;10,+5 第十行向下五行 ;
步长: 1~2 ,表示1,3,5...从1开始+2输出行;2~2 ,表示2,4,6...从2开始+2输出行
案例:
指定行输出

指定匹配字符输出
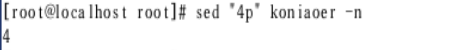
删除匹配行

删除4后输出没有,查看原文件还存在,因为此时修改的是内存中加载的文件,原文件要修改需要加-i
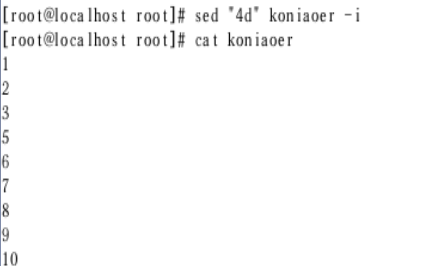
提取ip地址(ifconfig)
awk 处理文本文件的语言,文本分析工具
作用:通过提供编程语言的功能,如变量、数学运算、字符串处理等,使得对文本文件的分析和操作变得非常灵活和高效
语法: awk [参数] [pattern] {action} [file]
pattern:是用于匹配输入数据的模式。如果省略,则awk将对所有行进行操作。
{action}:是在匹配到模式的行上执行的动作。如果省略,则默认动作是打印整行
参数:
-F :指定输入字段的分隔符,默认是空格。使用这个选项可以指定不同于默认分隔符的字段分隔符
-v <变量名>=<值>: 设置 awk 内部的变量值。可以使用该选项将外部值传递给 awk 脚本中的变量
-f <脚本文件>: 指定一个包含 awk 脚本的文件。这样可以在文件中编写较大的 awk 脚本,然后通过 -f 选项将其加载
-v : 显示 awk 的版本信息
-h : 显示 awk 的帮助信息,包括选项和用法示例
内置变量:
FS:输入字段分隔符
OFS:输出字段分隔符
RS:输入记录分隔符(输入换行符)
ORS:输出记录分隔符
NF:当前行的字段个数
NR:行号
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存命令行所给的各参数
案例:
原样输出

根据指定列数输出

可知:
awk默认以空格为分隔符,多个空格也识别为一个
awk按行执行,可指定分隔符,默认空格
输出最后一列

NF代表最后一列
一次取出多列

加 ,会使用默认分隔符分割
指定内容输出

输出单行内容
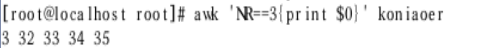
取ip地址
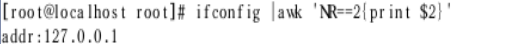
指定分隔符

指定输出分隔符
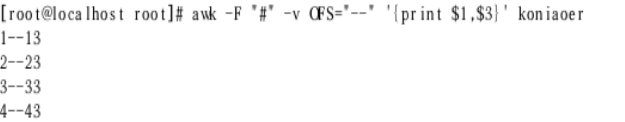
评论区